本地 AI 全栈部署:Ollama + Open WebUI + ComfyUI 图像生成
注: 本文由AI生成,ednovas编辑并审核发布。
本地 AI 全栈部署:Ollama + Open WebUI + ComfyUI
本文使用 NVIDIA DGX Spark 进行演示,你也可以在其他支持 Docker 的设备上进行部署,推荐ubuntu或者MAC系统。
NVIDIA DGX Spark 是 NVIDIA 推出的面向个人/小型团队的桌面级 AI 超级计算机,搭载 Grace Blackwell 架构,拥有 128GB 统一内存,非常适合在本地运行大语言模型和图像生成工作负载。本文将介绍如何在 DGX Spark 上一步步部署 Ollama + Open WebUI + ComfyUI,实现本地 LLM 聊天 + AI 图像生成的全栈 AI 工作站。
最终效果
- 💬 Open WebUI:一个美观的 ChatGPT 风格 Web 聊天界面,支持多模型切换(通过 Ollama 管理本地模型)
- 🖼️ ComfyUI:节点式 Stable Diffusion / FLUX 图像生成工作流引擎,作为 Open WebUI 的图像生成后端
- 在 Open WebUI 的聊天中直接输入 Prompt,即可调用 ComfyUI 后端生成图片并展示
一、前置准备
1.1 DGX Spark 基本配置
确保你的 DGX Spark 已完成初始设置,并且可以通过 NVIDIA Sync 或 SSH 连接到设备。
1.2 Docker 权限配置
通过 NVIDIA Sync 打开终端(Terminal),测试 Docker 是否可用:
docker ps |
如果出现 permission denied 错误,需要将当前用户添加到 docker 组:
sudo usermod -aG docker $USER |
再次运行 docker ps 确认无报错。
二、部署 Open WebUI + Ollama
Open WebUI 提供了一个集成 Ollama 的 Docker 镜像,一条命令即可同时部署 Ollama 推理后端和 Web 聊天界面。
2.1 拉取镜像
docker pull ghcr.io/open-webui/open-webui:ollama |
2.2 通过 NVIDIA Sync 配置(推荐)
如果你使用 NVIDIA Sync 管理 DGX Spark,可以通过自定义端口配置来自动化启动:
- 点击系统托盘的 NVIDIA Sync 图标,打开主窗口
- 点击右上角齿轮图标进入 Settings
- 切换到 Custom 标签,点击 Add New
- 填写以下信息:
- Name:
Open WebUI - Port:
12000 - Auto open in browser: ✅ 勾选
- Start Script:
- Name:
|
- 点击 Add 保存配置
2.3 手动 Docker 启动(替代方案)
如果不使用 NVIDIA Sync,也可以直接在终端运行:
docker run -d \ |
2.4 初始配置
- 浏览器访问
http://localhost:12000(首次启动需等待片刻) - 点击 Get Started,创建管理员账户
- 在左上角的模型下拉框中搜索并拉取模型,例如输入
gpt-oss:20b或llama3:8b,点击 Pull 从 Ollama 库下载 - 等待模型下载完成后,选择模型即可开始聊天
推荐的模型:
💬 通用聊天模型
| 模型 | 参数量 | 磁盘占用 | 运行内存 | 推荐场景 | 优点 | 缺点 |
|---|---|---|---|---|---|---|
deepseek-r1:70b |
70B | 43 GB | ~48 GB | 复杂推理、数学、代码 | 推理能力极强,思维链清晰,中文优秀 | 体积大,推理较慢,需要大内存 |
deepseek-v3.2:cloud |
— | 云端 | 云端 | 日常聊天、写作、代码 | 综合能力强,中文表现出色,速度快 | 依赖云端(cloud 版本) |
qwen3.5:397b-cloud |
397B | 云端 | 云端 | 高难度任务、长文本 | 当前最强开源模型之一,能力全面 | 仅 cloud 版本,参数量极大 |
llama4:latest |
16x17B (MoE) | 67 GB | ~72 GB | 多语言聊天、通用任务 | Meta 最新模型,多语言能力强,支持图文输入 | 中文能力略逊于国产模型 |
llama3.3:latest |
70B | 43 GB | ~48 GB | 通用聊天、轻量部署 | 成熟稳定,社区资源丰富 | 能力不如 Llama4 |
gemma3:27b |
27B | 17 GB | ~20 GB | 日常聊天、轻量推理 | Google 出品,效率高,支持多模态 | 中文能力一般 |
gemini-3-flash-preview:cloud |
— | 云端 | 云端 | 快速回复、多模态 | 速度极快,支持图文理解 | 仅 cloud,预览版本 |
gpt-oss:20b |
20B | 14 GB | ~16 GB | NVIDIA 生态适配 | OpenAI 开源模型,专为 DGX Spark 优化 | 社区资源较少 |
gpt-oss:120b |
120B | 65 GB | ~70 GB | 高质量对话、复杂任务 | 能力强,DGX Spark 生态深度适配 | 需要较大内存 |
glm-5:cloud |
— | 云端 | 云端 | 中文聊天、创作 | 智谱最新模型,中文理解出色 | 仅 cloud 版本 |
kimi-k2.5:cloud |
— | 云端 | 云端 | 长文本处理、中文聊天 | 超长上下文,中文能力强 | 仅 cloud 版本 |
kimi-k2-thinking:cloud |
— | 云端 | 云端 | 深度推理、思维链 | 内置思考过程,推理透明 | 仅 cloud 版本,速度较慢 |
minimax-m2.5:cloud |
— | 云端 | 云端 | 聊天、创作 | 中文流畅,创意写作能力好 | 仅 cloud 版本 |
richardyoung/deepseek-r1-32b-uncensored |
32B | 19 GB | ~22 GB | 无审查场景 | 无内容限制,推理能力强 | 第三方修改版,需自行评估风险 |
🔧 专用模型
| 模型 | 参数量 | 磁盘占用 | 运行内存 | 推荐场景 | 优点 | 缺点 |
|---|---|---|---|---|---|---|
qwen3-coder-next:cloud |
— | 云端 | 云端 | 代码生成、Debug、重构 | 代码能力顶级,支持多语言编程 | 仅 cloud 版本 |
qwen3-vl:235b-cloud |
235B | 云端 | 云端 | 图像理解、多模态分析 | 视觉理解能力强,支持图文对话 | 仅 cloud,参数量大 |
glm-ocr:latest |
— | 2.2 GB | ~3 GB | OCR 文字识别 | 专注 OCR 任务,识别准确率高,体积小巧 | 仅限 OCR 场景 |
💡 标注
cloud的模型通过云端 API 运行,不占用本地资源;无cloud标注的模型完全在本地运行,数据不出设备。DGX Spark 的 128GB 统一内存可轻松运行 70B 级别的本地模型。
更多模型可在 Ollama 模型库浏览:https://ollama.com/library
三、部署 ComfyUI
ComfyUI 是一个基于节点的 Stable Diffusion / FLUX 图像生成界面,我们将它部署为 Open WebUI 的图像生成后端。
3.1 安装 ComfyUI
推荐使用 Docker 部署 ComfyUI,也可以直接在 DGX Spark 上从源码安装:
方式一:源码安装
# 克隆仓库 |
方式二:Docker 部署
docker run -d \ |
方式三:源码安装 + systemctl 服务(推荐)
源码安装后,通过 systemd 将 ComfyUI 注册为系统服务,实现开机自启和后台常驻运行。
第一步:源码安装(同方式一)
# 选择一个安装目录,例如 /opt |
第二步:创建 systemd 服务文件
sudo vim /etc/systemd/system/comfyui.service |
写入以下内容(请根据实际路径和用户名修改):
[Unit] |
💡 将
<你的用户名>替换为实际运行用户(如nvidia),WorkingDirectory和ExecStart中的路径替换为你的 ComfyUI 实际安装目录。
第三步:启动并设为开机自启
# 重新加载 systemd 配置 |
常用管理命令:
# 停止服务 |
3.2 安装 ComfyUI Manager
ComfyUI Manager 是一个非常实用的插件管理器,可以方便地安装/管理各种自定义节点和模型。
cd ComfyUI/custom_nodes |
安装完成后重启 ComfyUI,在界面右侧会出现 Manager 按钮,通过它可以一键安装缺失的自定义节点。
3.3 下载 FLUX 模型
本教程使用 FLUX.1 Dev 模型进行图像生成,需要下载以下模型文件到 ComfyUI 对应目录:
| 模型文件 | 存放目录 | 说明 |
|---|---|---|
flux1-dev-fp8.safetensors |
models/unet/ |
FLUX UNet 主模型 (FP8 量化) |
t5xxl_fp8_e4m3fn.safetensors |
models/clip/ |
T5-XXL 文本编码器 |
clip_l.safetensors |
models/clip/ |
CLIP-L 文本编码器 |
ae.safetensors |
models/vae/ |
FLUX VAE 解码器 |
💡 这些模型可以从 HuggingFace 下载,搜索
black-forest-labs/FLUX.1-dev即可找到。
FP8 量化版本对显存更友好,DGX Spark 的 128GB 统一内存可以轻松运行完整精度版本。
3.4 验证 ComfyUI
访问 http://<DGX_SPARK_IP>:8188,确认 ComfyUI 界面正常加载。可以手动构建一个简单的 FLUX 工作流进行测试。
四、在 Open WebUI 中配置 ComfyUI 图像生成
这是本教程的核心部分:将 ComfyUI 作为 Open WebUI 的图像生成引擎,实现在聊天界面中直接生成图片。
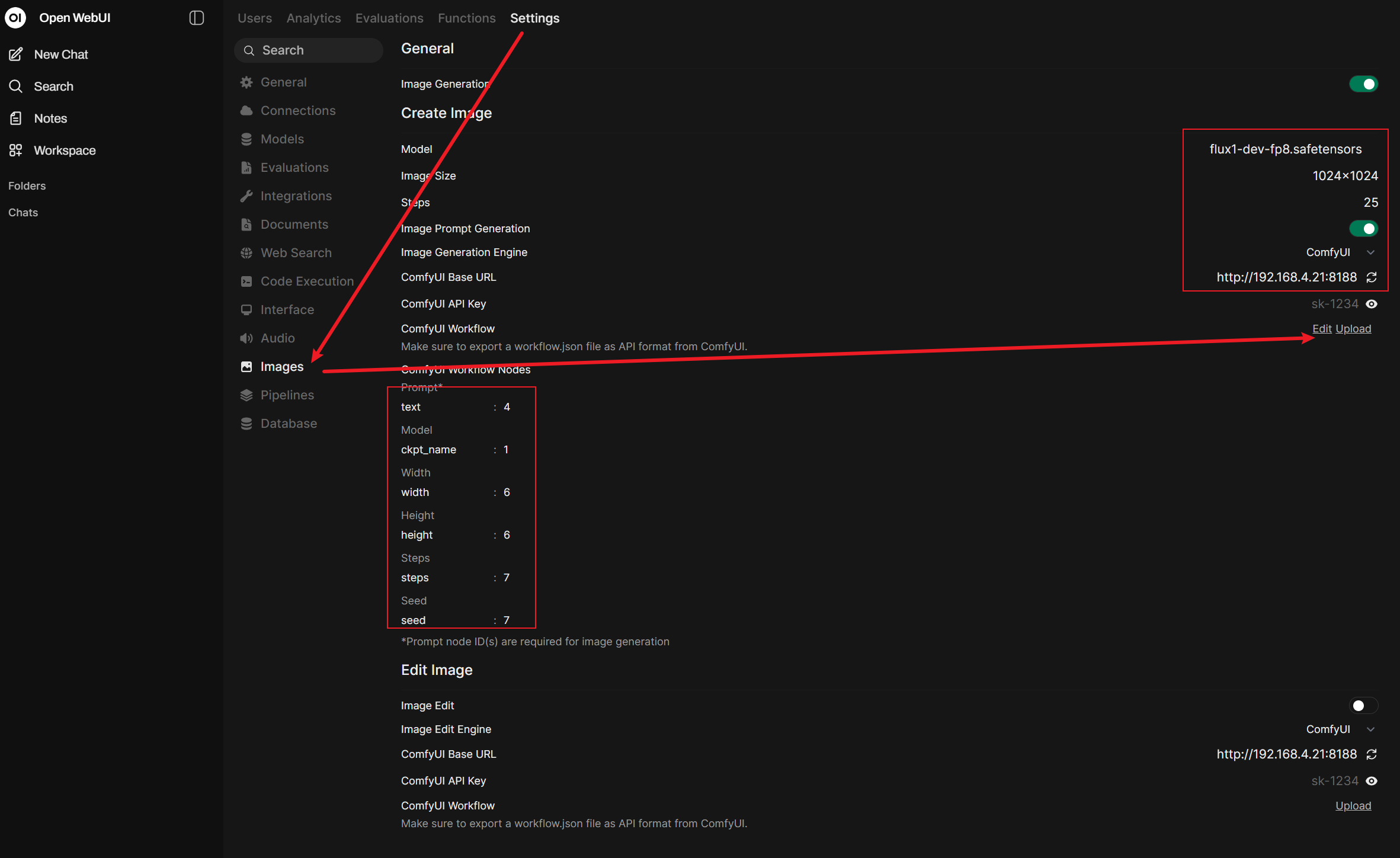
4.1 Open WebUI 图像生成设置
- 在 Open WebUI 中,点击左下角头像 → Admin Panel → Settings → Images
- 配置以下参数:
| 设置项 | 值 |
|---|---|
| Image Generation Engine | ComfyUI |
| ComfyUI Base URL | http://<DGX_SPARK_IP>:8188(例如 http://192.168.4.21:8188) |
| Image Prompt Generation | ✅ 开启(让 LLM 自动优化图像 Prompt) |
| Image Size | 1024×1024 |
| Steps | 25(或根据需要调整) |
4.2 上传 ComfyUI Workflow
Open WebUI 需要一个 API 格式 的 ComfyUI 工作流 JSON 文件来调用 ComfyUI。以下是本教程使用的 FLUX 工作流:
{ |
将以上 JSON 保存为文件,然后在 Open WebUI 的 Images 设置页面中,点击 ComfyUI Workflow 旁的 Edit / Upload 按钮上传。
4.3 配置 Workflow 节点映射
上传工作流后,Open WebUI 需要知道工作流中哪些节点对应哪些参数。在 ComfyUI Workflow Notes 部分配置节点映射:
| 参数 | 节点 ID | 说明 |
|---|---|---|
Prompt → text |
4 |
正向提示词输入节点 |
Model → ckpt_name |
1 |
UNet 模型加载节点 |
Width → width |
6 |
图像宽度 |
Height → height |
6 |
图像高度 |
Steps → steps |
7 |
采样步数 |
Seed → seed |
7 |
随机种子 |
4.4 工作流节点说明
上面的 FLUX 工作流由以下节点组成:
┌──────────────┐ |
⚠️ FLUX 模型的 CFG 值设为 1(即不使用 classifier-free guidance,这是 FLUX 的特性),负向 Prompt 留空。
五、使用:在聊天中生成图片
配置完成后,你可以在 Open WebUI 的聊天界面中生成图片:
- 在聊天窗口中点击输入框旁边的 图片生成 按钮(或在 Prompt 中触发图像生成)
- 输入图像描述 Prompt,例如:
a futuristic cyberpunk city at night, neon lights, rain reflections - Open WebUI 会将 Prompt 发送给 ComfyUI 后端执行 FLUX 工作流
- 等待 ComfyUI 完成推理后,生成的图片会自动显示在聊天界面中
💡 如果开启了 Image Prompt Generation,LLM 会先根据你的描述自动生成一个更优化的英文 Prompt,然后再发送给 ComfyUI,这样生成效果会更好。
六、常用操作
6.1 更新 Open WebUI
docker stop open-webui |
然后重新通过 NVIDIA Sync 或 Docker 命令启动。
6.2 停止服务
- Open WebUI: 在 NVIDIA Sync 中点击 Custom 区域的 ✕ 按钮,或
docker stop open-webui - ComfyUI:
Ctrl+C停止进程,或docker stop comfyui
6.3 清理数据
⚠️ 以下命令会永久删除所有数据和已下载的模型!
# 停止并删除容器 |
七、常见问题
Q: ComfyUI 生成图片时报错 “Missing nodes”?
使用 ComfyUI Manager 中的 Install Missing Custom Nodes 功能一键安装缺失节点。本教程的 FLUX 工作流使用的都是 ComfyUI 内置节点,通常不会遇到此问题。
Q: Open WebUI 无法连接 ComfyUI?
- 确认 ComfyUI 监听的是
0.0.0.0而非127.0.0.1 - 确认 ComfyUI Base URL 使用的是 DGX Spark 的局域网 IP(而不是 localhost,除非 Open WebUI 和 ComfyUI 在同一台机器上)
- 检查防火墙是否放行了 8188 端口
Q: 图片生成速度很慢?
- FLUX FP8 在 DGX Spark 上通常 20 步生成 1024×1024 图片需要约 30-60 秒
- 可适当降低 Steps 数量(如从 20 降到 15)来加速
- 确认是否启用了 GPU 加速(
--gpus=all)
Q: 如何添加更多模型?
在 ComfyUI Manager 中可以浏览和安装各种模型。也可以手动将 .safetensors 模型文件放到 ComfyUI 对应的 models/ 子目录中。

